Poster Presentation Australian Diabetes Society and the Australian Diabetes Educators Association Annual Scientific Meeting 2016
A Poll to determine ethnic differences of diabetes in Australia (#274)
Australia is a multicultural society but ethnic-specific data on diabetes in the community are not readily available and would be costly to collect. We explored the possibility of using surnames common to an ethnicity as proxies to extract ethnic-specific data from databases. An example would be to use HbA1c data from private pathology laboratories (which collect names but not ethnicities) to determine ethnic differences. Our Diabetes Centre database with self-nominated ethnicity (n=12443) was used to validate this concept. For this purpose, 3–10 surnames common to a particular ethnic group were determined from our database and their clinical data compared with those derived from all subjects in that ethnic group. Surnames (eg Lee) which could be found in more than one ethnic group were excluded.
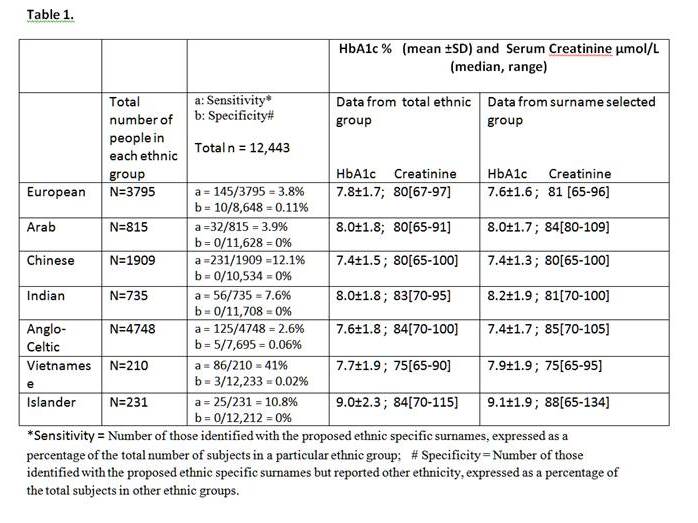
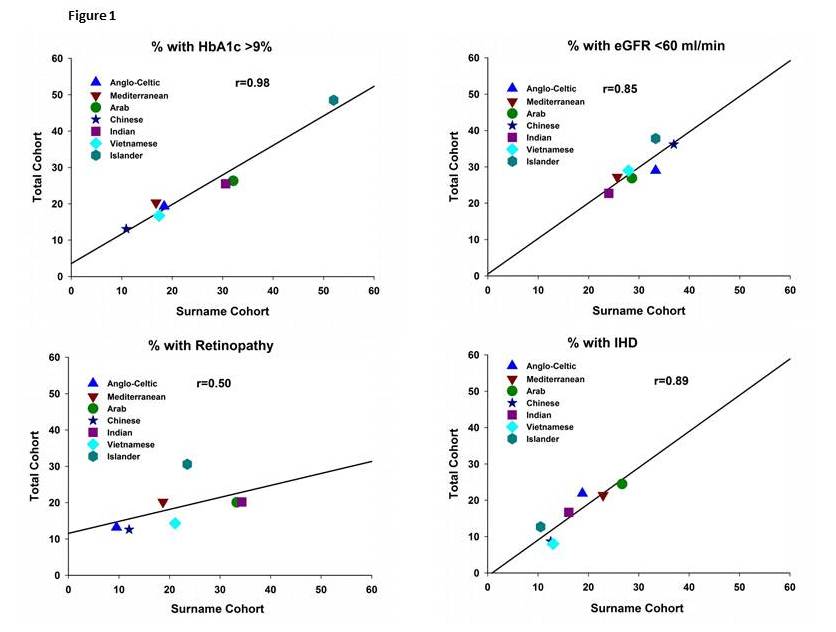
Results in Table 1 showed the high specificity and sensitivity of this Surname method in identifying seven ethnic groups. In ethnicities with greater number of surnames (eg Europeans) more surnames were required to generate an adequate selection of subjects and vice versa for ethnicities with fewer surnames (eg Chinese). Indigenous Australians could not be studied as most have anglicised names. The validity of this method is supported by good agreement shown in Table 1 for HbA1c and for serum creatinine data using the two methods of identifying ethnicities. There is also good concordance shown in Figure 1 between the total and surname selected cohorts when results are expressed as % of individuals with abnormalities (eg. HbA1c>9% ; eGFR< 60ml/minute ; history of IHD ; history of retinopathy).
We conclude that it is possible to use ethnic specific surnames as a surrogate to extract data representative of that total ethnic group. This cost effective method can be applied broadly to various databases to determine status and outcomes of diabetes of different ethnicities in our community.